"모바일 앱 환경에서는 latex 수식이 깨져 나타나므로 가급적 웹 환경에서 봐주시길 바랍니다."
오늘은 NLP 관련 Task 중에서 Machine translation (기계번역)에 대한 이야기를 하고자 한다.
RNN은 총 5편의 글이 계획되어져 있고, 오늘 4번째 글은 기계번역 TASK에 관련된 모델인 Seq2Seq에 대해 이야기하고, 다음 글에서는 Attention mechanism, Trasnformer에 대해 이야기하는 것으로 RNN 시리즈를 마무리할 것이다.
그리고 마지막으로 GAN에 대해 1~2편의 글을 게시한 이후 Deep dive into deep learning 시리즈는 마무리 될 예정이다.
Machine translation을 생각해보자. 아마 네이버 파파고나 구글 번역기 등 많이 이용해본 적이 있을 것이다.
이때 우리는 input으로 특정 언어의 문장들을 집어넣으면 output으로 원하는 언어의 문장들이 출력되는 것을 본다.
당연히 input으로 들어가는 문장들의 길이, output으로 나오는 문장들의 길이는 가변적이다.
이러한 기계 번역의 가장 대표적인 Neural network가 Seq2Seq이다.
이 모델은 Encoder - Decoder 구조로 이루어져 있고 각각이 RNN 또는 LSTM 등의 구조를 지니고 있다.
Encoder는 다양한 길이 (크기)를 가진 sequence data를 input으로 받아서 어떤 vector를 출력하고, Decoder는 이 vector를 입력으로 받아 output sequence에서 출력되어져야 할 단어 (token)들을 예측하는 역할을 수행한다.

영어를 한국어로 번역하는 Task를 생각해보자.
Input으로 "They are watching the movie."가 들어가야 한다. 이때 Encoder에서는 "They", "are", "watching" "the" 'movie" 토큰 단위로 시간 순서대로 input으로 받는다. 그리고 이들을 각각 Embedding하면서 특정한 벡터를 출력으로 내놓고, 이 벡터에는 위 단어들의 정보 (Feature)가 저장되어져 있다.
이제 Decoder는 이 Vector를 다시 input으로 받아서 번역된 문장을 생성해낸다.
정확히는 각 time step마다 가장 가능성이 높은 단어를 예측하여서 해당 단어를 출력하는 것이다.
여기서 그렇다면 중요한 역할을 하는 것은 위 그림에서 'State'라 적혀 있는 어떤 Vector일 것이다.
이 Vector를 우리는 'Context vector'라고 부를 것이다. Context vector는 '고정된' 크기의 Vector로서 우리가 미리 설정한 값을 차원/크기로 갖는다. 즉, input으로 들어오는 문장의 길이는 다양하지만, Encoder를 거쳐 나오는 Context vector의 크기는 고정되어져 있다.
Decoder는 Train 과 Test 시에 조금 다른데, Train 시에는 "ground-truth" label을 input으로 함께 받는다.
즉, 영어에서 한국어로 번역하는 Task를 생각해보면, 한국어로 번역된 문장, label을 Decoder는 input으로 받는다.
Decode는 매 time step마다 token을 output으로 내놓는다고 하였는데 Context vector, 그리고 이전 time step으로부터 받은 token을 함께 고려하여 현재 time step의 token을 output으로 내놓는다.
이 말을 다시 정리하면 다음과 같다.
만약 현재 time step $t$에서 '영화를' 이라는 token을 output으로 생성/예측해야 한다고 생각해보자.
이전 time step들 ($t-1, \cdots, 1$)에서 생성된 token '그들은'과 context vector를 input으로 받아서 '영화를'이라는 output을 함께 생성하도록 하는 것이다.
물론, 처음부터 정확한 단어를 출력하진 않을 것이고, label ('영화를')과의 차이를 오차로 하여 Backpropagation을 통해 학습이 진행되어진다.
그런데 여기서 한 가지 생각이 들 것이다. 만약 $t-1, \cdots, 1$ time step에서 생성된 단어들이 정확하지 않다면, 이 정보를 받아서 $t$ time step에서 단어를 생성할 때, 잘못된 정보를 고려하게 되는 것이기 때문에 오류가 계속해서 누적되지 않을까? 과거의 정보를 반영하여 현재의 정보를 생성하는 것인데, 과거의 정보가 잘못되어졌다면 당연히 현재의 정보도 잘못 출력되지 않을까? 이를 완화하기 위해 약간의 기술적 트릭을 사용하는데, Decoder에서는 $t$ time step의 output을 생성할 때, 이전 $t-1, \cdots, 1$의 출력된 단어 (생성된 토큰들)를 고려하지 않고 $t-1, \cdots, 1$에서의 label을 고려하도록 설계되어져 있다. 이를 Teacher forcing이라 하는데, 잘못된 정보가 계속해서 누적되는 것을 방지하기 위함이다.
이렇게 Train이 완료가 되면, Test시에는 우리는 정답 'label'을 함께 집어넣지 않는다.
즉, Test 시에 Decoder는 time step $t$의 output을 생성/예측할 때, $t-1, \cdots, 1$ output token을 고려하여 output을 생성하게 된다. 이때는 이전 time step의 label이 아니라 decoder output이 들어간다는 점이 Train과 Test 사이의 중요한 차이점 중 하나이다.

위 그림을 보면 영어를 프랑스어로 번역하는 Task이다.
Encoder 시에는 각 time step 단위로 token들이 들어가고 <eos>는 End-of-sequence의 약어로 input이 끝났다는 것을 모델에 알리는 토큰이다. 참고로 <bos>는 Beginning-of-sequence의 약어로 문장이 시작됨을 알리는 token이다.
위 그림에서는 생략됐지만 Encoder는 전체 tokens를 활용하여 'fixed-length' context vector를 출력하고 이를 Decoder는 input으로 받아서 매 time step마다 번역된 token을 출력하는 것이다.
그리고 Decoder 부분을 보면 input으로 이전 time step들에서 생성된 단어 (또는 label)들이 함께 들어가는 것을 볼 수 있는데, 이것이 앞서 말한 Teacher forcing이다.
이를 수학적으로 다시 한 번 복습하자.
Encoder가 하는 역할은 "고정된 차원/크기의" context vector $c$를 생성하는 것이라 하였다.
input sequence 가 $\{ x_1, x_2, \cdots, x_T \}$라고 해보자. 여기서 $x_t$는 $t$번째 token을 의미하고 $t$번째 time step에 Encoder input으로 들어갈 것이다.
time step $t$일 때, Encoder는 현재 hidden state $h_t$로 update를 진행할 것이다.
앞선 RNN 글에서 설명한대로 현재 input $x_t$와 이전 time step의 hidden state $h_{t-1}$을 input으로 받는다.
즉, 다음과 같은 함수로 표현할 수 있다.
$h_t = f(x_t, h_{t-1})$
그렇게 해서 생성된 매 time step의 hidden state를 활용해서 Encoder는 context vector $c$를 출력한다.
$c = q(h_1, h_2, \cdots, h_T)$
그냥 단순히 $h_T$를 context vector로 쓸 수도 있고, 아닐 수도 있다.
Decoder는 위 context vector $c$를 input으로 받아서 번역된 문장, $\{ y_1, y_2, \cdots, y_T^{\prime} \}$을 output으로 받아야 한다. 여기서 $T^{\prime}$은 output sequence의 길이이고 $y_t$는 $t$번째 time step에서 생성된 token을 의미한다.
앞서 이야기한대로 Decoder는 이전 time step의 output과 context vector를 input으로 받아서 $y_t$를 생성한다.
이를 다음과 같이 표현할 수 있다.
$\mathbb{P}(y_{t + 1} | y_1, \cdots, y_t, c)$
여기서 $y_1, \cdots, y_t$는 현재 time step에서의 hidden state $s_t$로 간단하게 표현하면 다음과 같이 된다.
$s_{t+1} = g(y_{t}, c, s_t)$
현재 hidden state로 업데이트를 진행한 이후, 즉 $s_{t-1}$에서 $s_t$로 업데이트를 진행한 이후, output layer에는 softmax function과 같은 것을 활용해 정답으로 가장 가능성이 높은 단어를 출력해낸다.
그렇다면 이렇게 학습된 모델을 어떠한 기준으로 평가할까?
기계 번역 모델에서 가장 대표적인 평가 기준이 BLEU인데 이에 대해 설명하고 본 글을 마무리하겠다.
먼저 필요한 용어를 몇 개 정의하고 넘어가겠다.
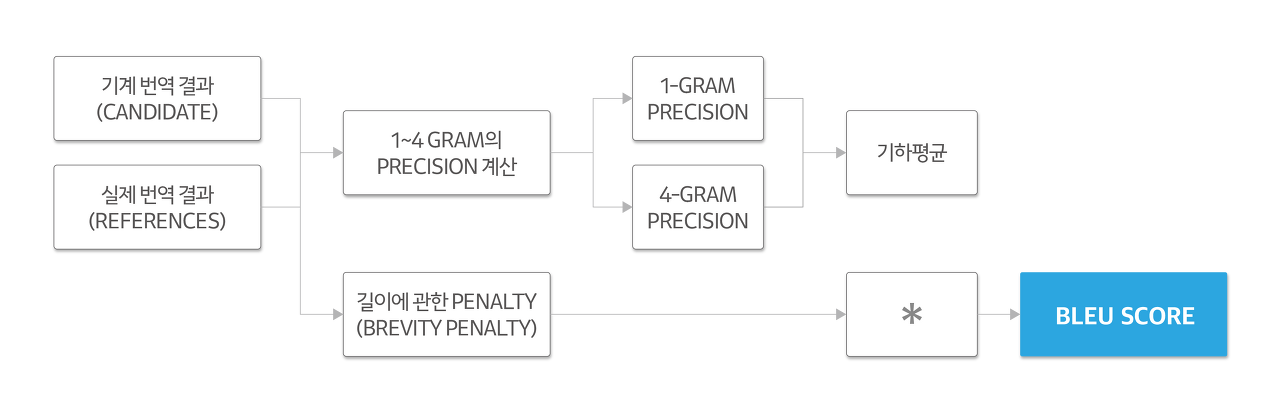
우리에게는 Machine Translation Task에서 2개의 문장을 비교할 것이다. 하나는 Decoder가 output으로 내놓은 기계 번역 결과이고 다른 하나는 사람이 번역한 결과, 즉 정답에 해당하는 문장일 것이다.
이 중 기계 번역 결과 문장을 'Candidate'이라 하고, 사람이 번역한 실제 번역 결과, 정답 문장을 'References'라고 한다.
이 둘을 비교하여 우리는 모델의 번역 성능을 평가한다.
BLEU score를 계산하는 방식은 다음과 같다.
여기서 처음 보는 용어가 하나 더 있을 수 있는데 N-gram이라는 용어이다.
N-gram이란 문장을 특정한 단위로 분할했을 때 인접한 토큰 (단어) N개를 모아놓은 것을 의미한다.
예를 들어 아래 문장의 1-gram, 2-gram, 3-gram은 다음과 같다.
"나는 오늘 여자친구와 함께 저녁을 먹었다."
1-gram : "나는", "오늘", "여자친구와", "함께", "저녁을", "먹었다."
2-gram : "나는 오늘", "오늘 여자친구와, "여자친구와 함께", "함께 저녁을", "저녁을 먹었다."
3-gram : "나는 오늘 여자친구와", "오늘 여자친구와 함께", "여자친구와 함께 저녁을", "함께 저녁을 먹었다."
그러면 이제 Candidate과 Reference 사이의 N-gram 정확도를 측정하는데 이는 다음과 같이 이뤄진다.
1-gram의 정확도 (precision)는 Candidate의 단어가 Reference에 나온 최대 개수와 Candidate의 총 단어 개수로 구할 수 있다.
여기서 $m_{max}$는 Candidate의 단어가 Reference에 나온 최대 개수, $w_t$는 candidate의 총 단어 개수이다.

예를 들어 Reference는 앞선 문장 "나는 오늘 여자친구와 함께 저녁을 먹었다."라고 하고, Candidate은 "나는 어제 여자친구와 따로 저녁을 먹었다."라고 해보자.
그러면 두 문장 사이의 1-gram 정확도는 다음과 같다.
우선 $w_t$는 6이다. 그리고 "나는"의 $m_{max}$는 1이다. "따로"라고 하는 단어는 Reference에 등장하지 않으므로 $m_{max}$는 0이다. 이러한 방식으로 Candidate 1-gram 단위로 $P$를 계산하면
$P = \frac{4}{6} = \frac{2}{3}$
이 나온다.
이러한 방식으로 2-gram, 3-gram, 4-gram precision들을 계산한다.
그리고 'Brevity penalty'가 있는데 이는 문장의 길이를 활용해서 penalty를 가하는 것이다.

여기서 $r$ 은 Reference의 길이, $c$는 Candidate의 길이이다.
이렇게 구한 1-gram precision부터 4-gram precision까지의 값들을 '기하평균'을 내고, Brevity penalty와 곱해준다.
이 값이 BLEU score가 된다.
'Deep dive into Deep learning' 카테고리의 다른 글
| Deep dive into Deep learning Part 25 : Transformer (0) | 2023.06.24 |
|---|---|
| Deep dive into Deep learning part 24 : RNN(5) (1) | 2023.06.16 |
| Deep dive into Deep learning part 22 : RNN(3) (2) | 2023.05.31 |
| Deep dive into Deep learning part 21 : RNN (2) (0) | 2023.05.26 |
| Deep dive into Deep learning part 20 : RNN (1) (0) | 2023.05.20 |




댓글