"What is deep learning?"
최근 서비스를 시작한 chatGPT4o (https://openai.com/blog/chatgpt) 에 대한 화두가 커지면서, 인공지능에 대한 제2의 알파고 붐이 일어나고 있다.
AI 기술은 알파고와 이세돌 프로 구단과의 바둑 대결이 있던 2016년, 커제 프로 구단과의 바둑 대결이 있던 2017년 이후 현재까지 꾸준히 빠르게 발전하고 있었지만, 일반 대중들이 그것을 인지하기는 쉽지 않았다.
하지만, 오픈AI에서 공개한 대규모 언어 모델 (Large Language Model, LLM)인 chatGPT가 상당히 놀라운 성능을 보여주면서 세계는 다시 한 번 인공지능에 대한 붐에 휩싸이고 있다.
그렇다면, 현재 인공지능의 원천이 되는 기술인 Deep Learning (심층학습)은 무엇일까?
Deep Dive into Deep Learning의 첫 번째 글로 딥러닝에 대해 이야기해보고자 한다.
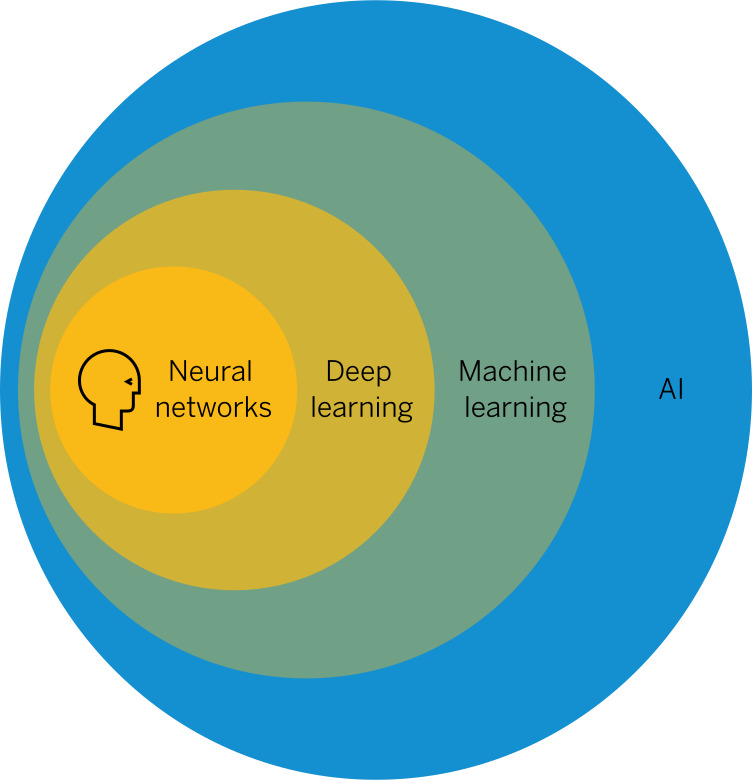
딥러닝에 대한 이야기를 하기 위해서는 먼저 머신러닝을 이야기하지 않고 넘어갈 수 없다.
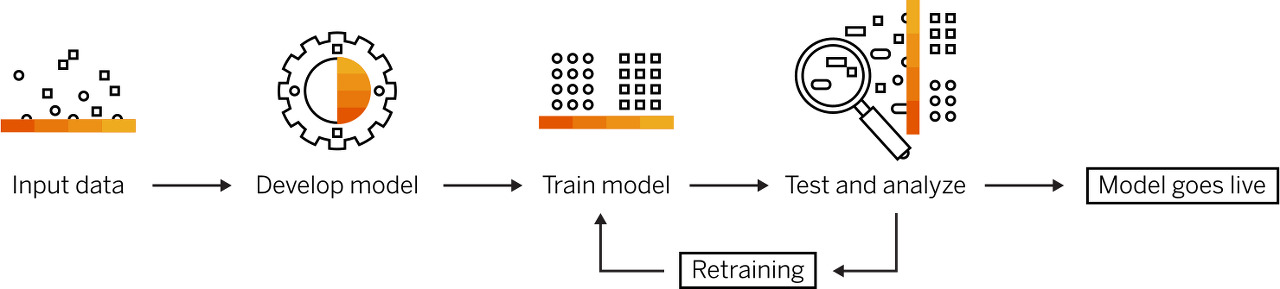
머신러닝의 프로세스에 대해 그림으로 잘 표현한 이미지를 첨부하였다.
위 프로세스는 머신러닝, 딥러닝에서 가장 중요한 영역에 대해 모두 담고 있다.
1. 데이터 (Data)
2. 모델 (Model)
3. 학습 (Train)
4. 평가 (Test)
약간의 과장을 하자면 위 4가지가 결국 딥러닝과 머신러닝의 전부이고 모든 것이다.
앞으로 Deep DIve into Deep Learning 시리즈에서 하고자 하는 이야기들도 결국 위 4가지에 대해 자세하게 이야기하는 것 뿐이다. 데이터에 대하여 이야기를 할 것이고, 모델 (Neural networks) 에 대해서 이야기를 할 것이고, 학습에 대해서 이야기를 할 것이고, 평가에 대해서 이야기를 할 것이다.
특히, 학습에 대한 이야기는 본 블로그에서 다룰 주제 중 하나인 Optimization과도 큰 관련이 있어, Deep Dive into Optimization에서 조금 더 수학적으로 자세하게 이야기를 할 예정이다.
다시 본론으로 돌아와서, 그렇다면 머신러닝이란 무엇인가? 그리고 딥러닝과 머신러닝의 차이점은 무엇인가?
인간은 살아가면서 수많은 의사결정을 수행한다.
그 의사결정을 특정한 모델이 도와주도록, 혹은 상당히 복잡한 의사결정의 경우에는 컴퓨터의 계산 능력을 통하여 빠른 결정을 내릴 수 있도록 모델을 학습시키는 것이 바로 머신러닝이다.
예를 들어 의사는 눈앞의 환자가 병에 걸렸는지, 걸리지 않았는지 또는 어떤 병에 걸렸는지 등을 판단하기 위해 여러 검사와 환자와의 질의응답을 통한 진료 행위를 한다. 의사에게 있어서 검사 결과와 환자와의 문답을 통해 얻은 정보들이 모두 '데이터'이다.
그 데이터를 의사는 자신이 가지고 있는 의학적 지식을 통해 분석한다. 이때 의사가 공부 / 경험 등을 통해 가지고 있는 의학적 지식이 일종의 '모델'이다. 물론 지식은 오감을 통해 '감각'할 수 없는 추상적인 것이지만, 의사는 자신이 가지고 있는 의학적 지식으로 모델링 된 나름의 틀 (frame)을 가지고 있다. 이 모델은 그동안 '공부'와 '경험'을 통해 의사가 얻은 것이다.
즉, 훈련/학습을 통해 의사는 나름의 모델을 얻게 되었다. 기존에 학습된 모델을 통해 의사는 새로운 환자로부터 얻은 데이터들을 활용하여 의사 결정을 수행할 것이다.
자, 지금 비유적으로 설명한 이 내용은 우리는 사람을 예시로 들어 설명하였다.
이제 이것을 컴퓨터로 바꾸면 그것이 곧 머신러닝이고 딥러닝이다.
컴퓨터는 (일단 지금은 컴퓨터라고 표현하겠다.) 어떤 사람의 수많은 데이터를 입력으로 받았다. 이 데이터에는 이 사람의 키, 몸무게, 나이, 흡연 유무, 음주 유무, 특정 증상들의 유무, 등등 무수히 많은 정보들이 담겨 있다. 이제 컴퓨터는 새로 입력받은 이 데이터를 통해서 이 사람이 특정한 병에 걸렸는지, 걸리지 않았는지를 분류 (classification) 하는 의사 결정을 수행해야 한다.
이 컴퓨터는 그동안 많은 사람들의 정보들을 통해서 학습이 이루어졌다. 즉 이미 수많은 데이터 집합을 통해서 학습된 나름의 모델을 가지고 있는 것이다. 이제 이 컴퓨터는 나름의 의사결정의 기준을 가지고 있고, 이를 바탕으로 새로운 데이터가 양성인지 (병에 걸렸는지), 음성인지 (병에 걸리지 않았는지)를 판단할 것이다.
이것이 머신러닝이다. 그리고 우리가 머신러닝을 통해 하고자 하는 것들이다.
그렇다면 마지막으로 머신러닝과 딥러닝의 차이점은 무엇일까?
이 또한 앞의 예시를 통해 설명할 수 있다.
우리는 컴퓨터에게 입력으로 집어넣은 데이터에는 '키', '몸무게', '나이', '특정 증상들의 유무' 와 관련된 정보들이 담겨져 있다고 하였다. 이것들은 앞으로 특징 (feature) 이라고 부를 것이다.
단순히 데이터만으로는 의사 결정을 내릴 수 없다. 데이터에서 의사 결정을 수행하기 위해서는 의미 있는 특징을 추출해야만 한다.
이 특징을 추출하는 작업을 feature engineering이라고 하는데, 이를 사람이 수행하냐, 기계가 학습 과정에서 자동적으로 수행하느냐가 현재의 머신러닝과 딥러닝을 구분하는 가장 큰 요소이다.
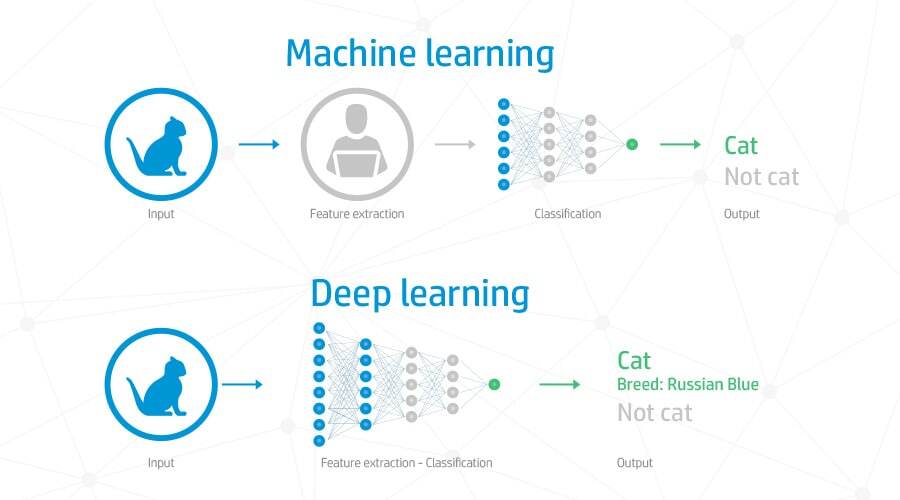
위 사진에서 보면 머신러닝에는 Feature extraction을 사람이 수행하고 있지만, 딥러닝에서는 특정 모델이 수행하고 있음을 알 수 있다.
결국 머신러닝, 딥러닝 모두 '의사 결정'을 컴퓨터가 내리게 하기 위해 컴퓨터를 학습시키는 일련의 과정을 표현하는 개념이다.
다음 포스트에서는 조금 더 세부적으로 딥러닝을 나눠보고자 한다.
일반적으로 현재의 딥러닝을 지도 학습 (Supervised learning), 비지도 학습 (Unsupervised learning), 강화 학습 (Reinforcement learnig) 으로 구분하는데 이는 학습 방법에 따른 구분이다.
다음 글에서는 각각에 대해 이야기해보고자 한다.
'Deep dive into Deep learning' 카테고리의 다른 글
| Deep dive into Deep learning part 6. - Updated (0) | 2023.03.17 |
|---|---|
| Deep dive into Deep learning part 5. - Updated (1) | 2023.03.13 |
| Deep dive into Deep Learning Part 4. - Updated (0) | 2023.03.09 |
| Deep dive into Deep Learning Part 3. - Updated (0) | 2023.03.07 |
| Deep dive into deep learning part 2. - Updated (0) | 2023.03.05 |




댓글